Co weryfikujemy
NIC (network interface card) to popularnie zwana sieciówka.
To co rozróżnia karty sieciowe to rodzaj sieci jaki potrafia obsługiwac,
jak Ethernet, Token Ring, czy własnie Gigabit którym my sie zajmiemy.
Myrinet - gigabitowy system sieci, o bardzo małym narzucie danych kontorlnych, przez co jest dużo wydajniejszy od popularnych standardów jak Ethernet, ma wiekszą przepustowość, mniej kolizji na kablu i mniej angażuje procesor host'a. Pierwsza generacja Myrinet'ów zapewniała przepustowość rzędu 512 MBit/s w obie strony, w tej chwili ta wartość wzrosła do 2 GBit/s. Co ważne rzeczywiście osiągana przepustowość jest bardzo bliska teoretycznej maksymalnej przepustowości sieci.
Berkeley-VIA to implementacja Virtual Interface Architecture,
swego rodzaju nakładki na Myrinet.
Udostępnia bezpośredni dostęp do NIC omijając nawet jądro
(w którym identyczne operacje przechodzą przez szereg filtrów,
testów i tym podobnych nakładek)
- stąd zakłada się że Berkeley-VIA udostępnia niemal fizyczną przepustowość łączy.
testy jakie przeprowadzono, wykazały że:
-
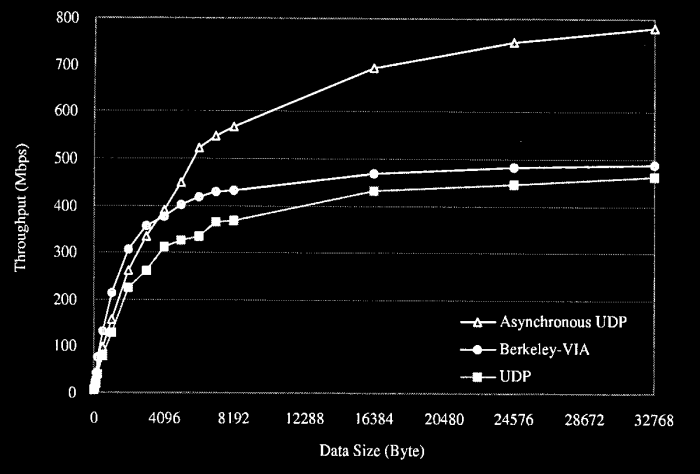
Berkeley-VIA ma większą przepustowość niż UDP na Myrinet'cie, ale już
dużo mniejszą niż tzw. Asynchroniczne UDP jeśli brac pod uwagę pakiety
większe niz 4Kb
-
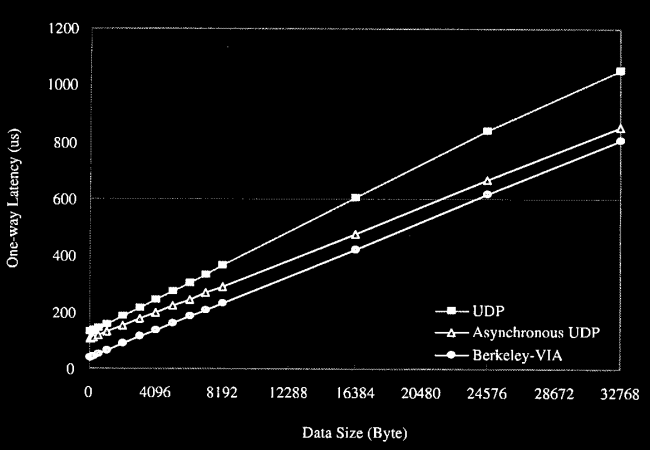
Berkeley-VIA podczas transmisji ma mniejszy czas oczekiwania
niż UDP i Asynchroniczne UDP.
Zdecydowano sie zweryfikować Myrinet w celu znalezienia wąskiego gardła. Myrinet NIC posiada trzy kanały DMA oraz własną pamięc i procesor, a dodatkowo interakcja Myrinet'u z host'em jest bardzo złożona - więc weryfikacja do prostych nie należy. Po kolei przedstawię jak:
- najpierw zbudowano diagramy przejść stanów aby wymodelować Myrinet
- potem przetłumaczono je na specyfikacje w Promeli
- na koniec wyprowadzono formuły weryfikacji, i zweryfikujemy je w SPIN'nie
budowa Myrinet NIC
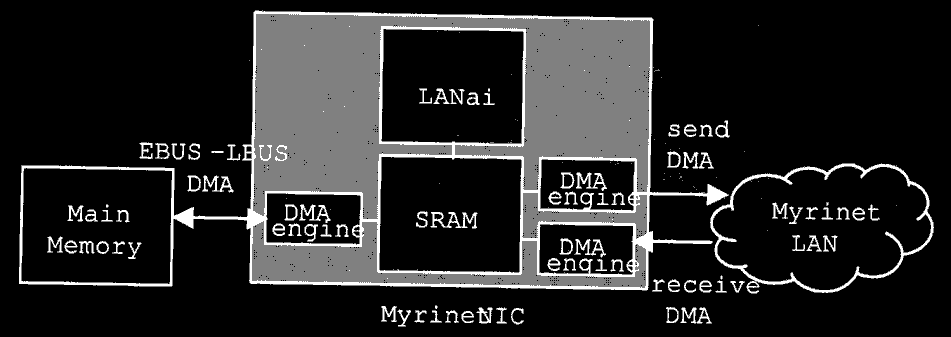
Myrinet NIC zawiera:
- procesor RISC nazwany LanAI
- pamięć SRAM (Static Random Access Memory) - przetrzymuje odebrane dane lub dane do wysłania
-
trzy szyny DMA:
- EBUS-LBUS DMA - odpowiedzialna za transfer danych pomiedzy SRAM'em a pamiecią główną
- send-DMA - odpowiedzialne za transfer danych z SRAM'u do wlaściwej sieci
- receive-DMA - odpowiedzialne za transfer danych z sieci do SRAM'u
modelowanie
Analizowano dwa oprogramowania sprzętowe:
- Lanai Control Program (LCP) - obsługującym stronę Berkeley-VIA
- Myrinet Control Program (MCP) - oblsługującym stronę tradycyjnych protokołów jak TCP czy UDP
-
LCP - Lanai Control Program
składa sie z czterech modułów: hostDma, lcpTx, lcpRx i main.
Poszczególne diagramy przejść stanów wyglądają tak:
Moduły zostały wyspecyfikowane w Promeli jako osobne procesy.
Wszystkie interakcje pomiedzy modułami sa wykonywane synchronicznie, przy czym te interakcje zaimplementowano jako po dwa kanały dla każdego procesu: jeden do przesyłania argumentu, a drugi dla zwracanej wartości.
Zdarzenia sa również przesyłane jako argumenty lub wartości zwracane.Przykład:
-
MCP - Myrinet Control Program
MCP wchodzi w skład Myrinet'u i oblsługuje komunikacje tradycyjnymi protokołami jak TCP czy UDP.
Składa się z pięciu modułów:
- hostSend - odpowiedzialny za transfer danych z pamięci głównej do SRAM'u
- netSend - odpowiedzialny za transfer danych z SRAM'u do sieci
- hostReceive - odpowiedzialny za transfer przysłanych danych z SRAM'u do pamięci głównej
- netReceive - odpowiedzialny za odbiór danych z sieci do SRAM'u
- main - odpowiedzialny za wołanie metod pozostałych modułów, w zależności od zdarzeń
Porównując LCP do MCP: podstawowa różnica to że w tym drugim każdy moduł ma wiele punktów wejścia. Oznacza to tylko tyle że podczas gdy w LCP wychodząc z stanu początkowego metoda kończyła działanie dopiero po dotarciu z powrotem do stanu początkowego, bez czekania na jakiekolwiek zdarzenia, o tyle w MCP sterowanie może zostać przerwane w niemal dowolnym stanie, oraz wznowione później w punkcie w którym ostatnio przerwało.
Podobnie jak w LCP komunikacja pomiędzy modułami odbywa się za pomocą dwóch kanałów komunikacyjnych w Promeli. Zdarzenia są składowane w kanale nazwanym Events, a powołując się na jego zawartość moduł główny woła odpowiednie metody.
Przykład:
porównanie oprogramowań pod kątem przepustowości
Największy wpływ na szybkość przesyłania danych w NIC ma stopień
wykorzystania kanałów DMa.
Maksymalne przepustowości są osiągane gdy EBUS-LBUS DMA działa równolegle
z kanałami send-DMA i receive-DMA.
Wyprowadzono więc formuły LTL do weryfikacji wykorzystania kanałów DMA:
-
LCP
-
<> (LcpTxInvokeRx && HostDmaBusy && !LcpTxHostDma)
czyli: czy moduł lcpTx może inicjować send-DMA, podczas gdy moduł hostDma używa EBUS-LBUS DMA kopiując dane z pamięci głównej do SRAM? -
<> (LcpRxReady && HostDmaBusy && !LcpRxHostDma)
czyli: czy moduł lcpRx może inicjować receive-DMA, podczas gdy moduł hostDma używa EBUS-LBUS DMA kopiując dane z pamięci SRAM do głównej?
-
-
MCP
-
<> (HostSendDma && NetSendBusy)
czyli: czy moduł netSend może inicjować operacje send-DMA podczas gdy moduł hostSend korzysta z szyny EBUS-LBUS DMA? -
<> (HostReceiveDma && NetReceiveBusy)
czyli: czy moduł netReceive może inicjować operacje receive-DMA podczas gdy moduł hostReceive korzysta z szyny EBUS-LBUS DMA?
-
Jeśli szyny DMA miałyby działać równolegle, weryfikacja każdej z powyższych
formuł powinna dać odpowiedź "prawda".
I o ile SPIN dla MCP dał takie właśnie odpowiedzi, to dla LCP odpowiedzią na
obie formuły był "fałsz"! - te wyniki wyjaśniają dlaczego osiągi Berkeley-VIA
są tak ograniczone.
Symulacja dowiodła również, że LCP wykorzystuje DMA sekwencyjnie (szeregowo), podczas gdy MCP wykorzystuje je równolegle. Identyczne wyniki osiągnięto przy symulacjach "interaktywnych" i losowych.
Wykonano dodatkowo jeszcze jeden test, na to czy szyna EBUS-LBUS DMA jest w jednym czasie wykorzystywana przez maksymalnie jeden moduł (ta szyna prowadzi dane zarowno z pamięci głównej do SRAM, jak i w druga strone - stąd moduły powinny czekać aż DMA przestanie być obciążone jeśli inne moduły z niego korzystają)
Formuły wyglądały jak niżej:
-
LCP
[] ! (LcpTxHostDma && LcpRxHostDma)
czyli: lcpTx nie może używać z EBUS-LBUS DMA w czasie gdy korzysta z niej moduł lcpRx -
MCP
[] ! (HostSendDma && HostReceiveDma)
czyli: moduł hostSend nie może używać EBUS-LBUS DMA w czasie gdy korzysta z niej moduł hostReceive
Ta weryfikacja dowiodła, że zarówno LCP jak i MCP spełniają postawione im wymogi
Podsumowując
Powyżej prześledzono wąskie gardło oprogramowanie Myrinet'u.
Wyniki pokazały ze:
- LCP wykorzystuje DMA szeregowo, co prowadzi do zmniejszenia szybkości przesyłania danych w Berkeley-VIA.
-
MCP w pełni wykorzystuje wszystkie trzy kanały DMA:
jego wewnętrzna struktura jest bardziej wyszukana niż LCP, moduły maja wiele punktów wejscia (w porównaniu z pojedynczymi punktami wejscia w LCP) a takie rozwiązanie pozwala działać kanałom DMA równolegle.